
Updates
- [2025/06/18] Updated ArXiv with better results! [New!]
- [2025/05/31] Code and model weights available.
- [2025/05/25] ArXiv preprint available.
Updates
We introduce VTool-R1, one of the first frameworks that trains VLMs to generate multimodal chains of thought by interleaving text and intermediate visual reasoning steps. VTool-R1 integrates Python-based visual editing tools into the RFT process, enabling VLMs to learn when and how to generate visual reasoning steps that benefit final reasoning. Trained with outcome-based rewards tied to task accuracy, our approach elicits strategic visual tool use for reasoning without relying on process-based supervision. Experiments on structured visual question answering over charts and tables show that VTool-R1 enhances reasoning performance by teaching VLMs to "think with images" and generate multimodal chain of thoughts with tools.
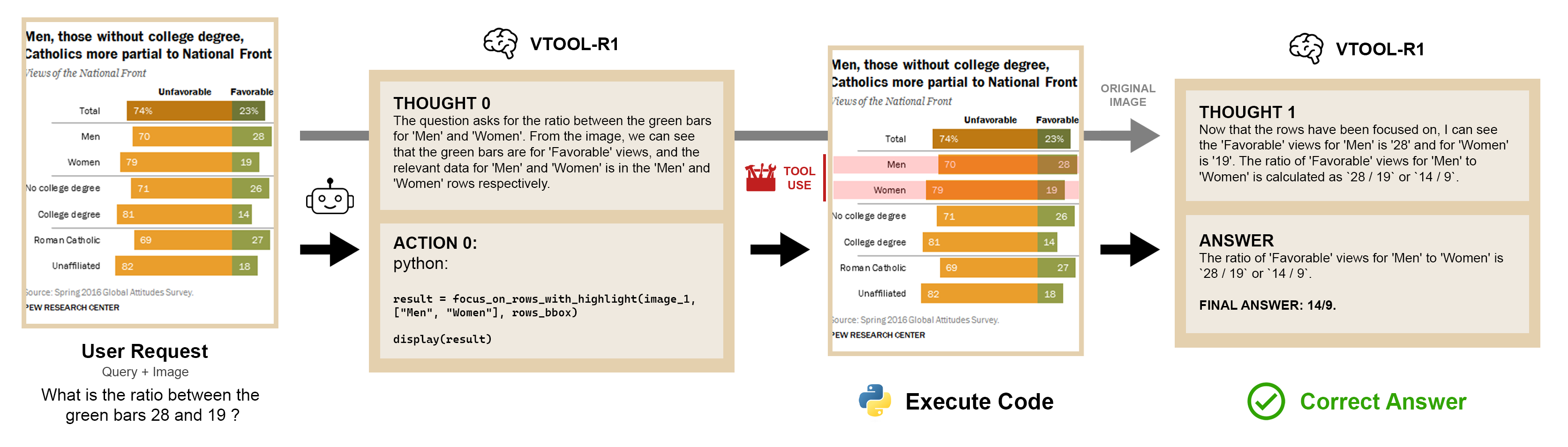
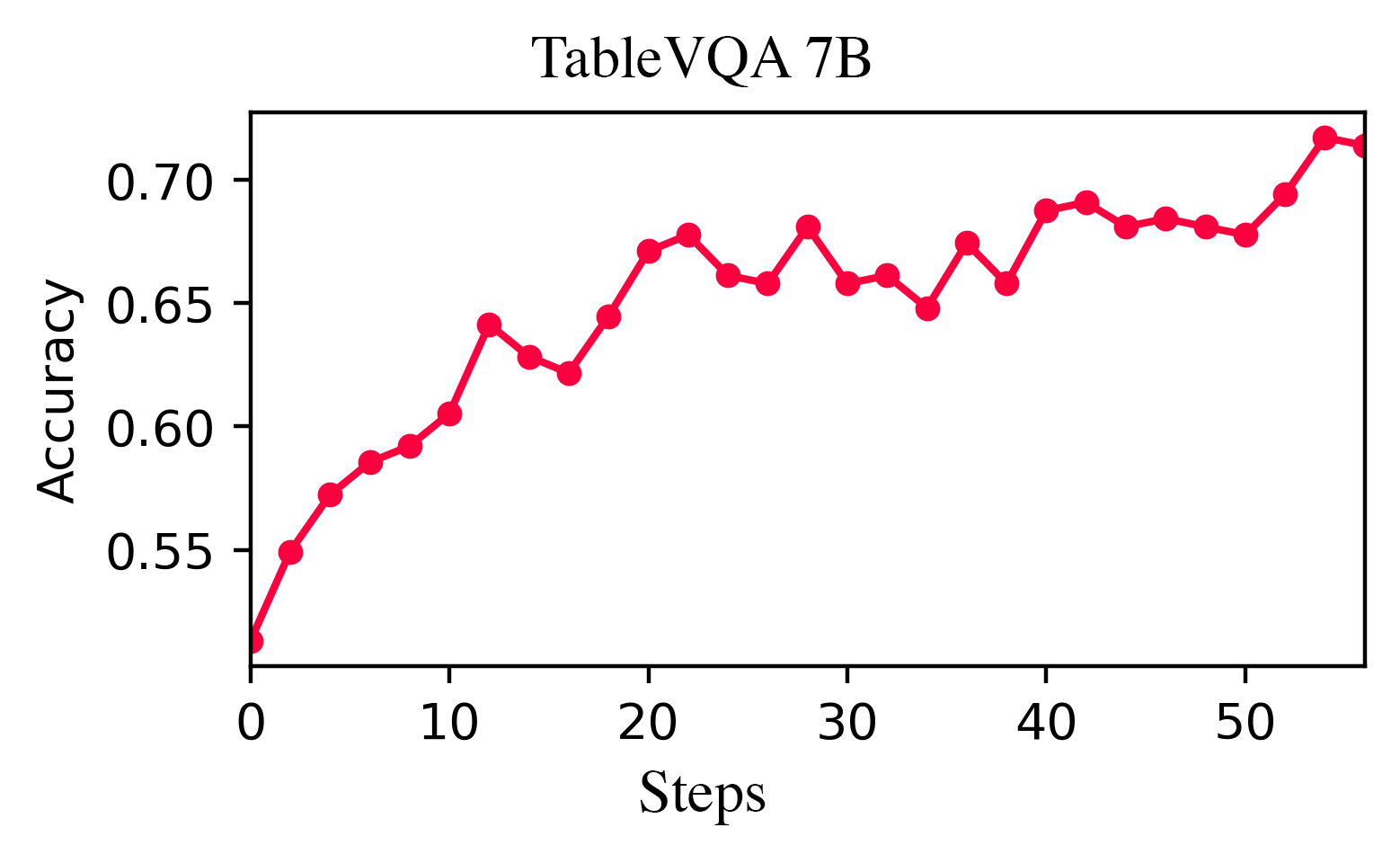
We released the full training and evaluation code. We used EasyR1, a fork of veRL with support of vision language models for training.
For training and validation, we used datasets and tools from ReFocus. Please follow the instructions in our repository.
If you find our project helpful, please cite:
@misc{wu2025vtoolr1vlmslearnthink,
title={VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use},
author={Mingyuan Wu and Jingcheng Yang and Jize Jiang and Meitang Li and Kaizhuo Yan and Hanchao Yu and Minjia Zhang and Chengxiang Zhai and Klara Nahrstedt},
year={2025},
eprint={2505.19255},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.19255},
}
If you find the dataset helpful, please consider citing Refocus paper:
@misc{fu2025refocusvisualeditingchain,
title={ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding},
author={Xingyu Fu and Minqian Liu and Zhengyuan Yang and John Corring and Yijuan Lu and Jianwei Yang and Dan Roth and Dinei Florencio and Cha Zhang},
year={2025},
eprint={2501.05452},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.05452},
}
This research used the Delta advanced computing and data resource which is supported by the National Science Foundation (award OAC 2005572) and the State of Illinois. Delta is a joint effort of the University of Illinois Urbana-Champaign and its National Center for Supercomputing Applications.
We would also like to acknowledge Bowen Jin (author of Search-R1) and Xingyu Fu (author of Refocus) for their valuable suggestions and contributions to our project.
This work was supported by the National Science Foundation grants NSF CNS 21-06592, NSF OAC 18-35834 KN, NSF CNS 19-00875 and NSF CCF 22-17144. Any results and opinions are our own and do not represent views of National Science Foundation.